
Retrieval-Augmented Generation (RAG) is an innovative method that combines retrieval capabilities with generative models to produce more accurate and relevant responses. By leveraging external data sources, RAG overcomes the common limitations of Large Language Models (LLMs), such as outdated information and the risk of hallucinations (misinformation). Additionally, RAG offers a significant advantage: it can be trained with proprietary information without the risk of data leakage to LLM vendors, thereby safeguarding corporate confidentiality.
But how can we ensure that RAG effectively addresses these challenges? This becomes even more critical when RAG is applied to regulatory document-based use cases, where the volume of documents is immense. Evaluating such systems becomes increasingly complex, particularly when manual benchmarking is inefficient and testers lack deep domain knowledge of the documents. This is where automation in benchmarking becomes essential to ensure evaluations are consistent, fast, and accurate.
Benchmarking refers to the evaluation process using measurable metrics to assess the quality and reliability of the responses generated by RAG. In this article, I will share my journey in discovering the optimal benchmarking approach for RAG. The process was not without its challenges, as I navigated the delicate balance between maintaining quality control and achieving time efficiency. Ultimately, this journey led me to a benchmarking tool I believe to be the best: Giskard.
The Benchmarking Journey for Evaluating RAG
Initial Phase: Manually Creating a Test Set for Optimal Quality
The first step in benchmarking is to create a test set as a standard for evaluation. This test set was manually crafted by sampling questions from various relevant topics based on proprietary information used to train the RAG system. In this example, we used 12 documents from the regulations of the Deposit Insurance Corporation (PLPS). The sampling process was heuristic, selecting 8-10 random questions (random sampling) from each document.
This manual approach was chosen because it provides complete control over the test set’s quality. Every element can be ensured to be relevant and capable of supporting an accurate evaluation of the RAG system. Although time-consuming, this step helps avoid biases or errors that might arise from automated methods.
Manual Testing: The First Step Toward Accurate Evaluation
Once the test set was created, questions from the test set were presented to the RAG system, and the model’s responses were manually compared against the reference documents. This manual approach ensures that every answer is assessed based on its relevance and coherence with the source documents. The results of this manual testing serve as an essential initial benchmark, offering a deep understanding of the strengths and weaknesses of the RAG model.
Scalability Challenges: The Need for Automation
While the manual approach is effective for small-scale evaluations, challenges arise as the scale of evaluation increases. Automation becomes necessary to save time and effort without compromising the quality of the evaluation. However, this automation must maintain the accuracy standards established during manual testing.
Exploring Tools for Benchmarking RAG
RAGAS: The Evaluation Standard for RAG
RAGAS (Retrieval-Augmented Generation Assessment System) is an evaluation framework offering various metrics to measure the quality of a RAG model’s responses. Below is an explanation of these metrics along with usage examples:
- Faithfulness
Faithfulness assesses the extent to which the model’s response is supported by information in the reference document. The response must align with the source or reference document without introducing unsupported information.
Example:
Prompt: “When did World War II end?”
- Model Response: “1939.”
- Reference Answer: “World War II ended on September 2, 1945.”
The model’s response has low faithfulness as it does not match the facts in the reference document.
- Answer Relevancy
Answer relevancy evaluates whether the model’s response is relevant to the question, even if it is not entirely accurate or detailed. This metric measures the response’s contextual alignment with the question.
Example:
Prompt: “When did World War II end?”
- Model Response: “In 1945.”
- Reference Answer: “World War II ended on September 2, 1945.”
The model’s response has high answer relevancy because it is relevant to the question, though less specific.
- Context Precision
Context precision measures how precise and relevant the portion of the document retrieved by the model is in generating the response. Higher precision indicates more relevant context usage.
Example:
Prompt: “When did World War II end?”
- Model Response: “World War II, a global conflict involving many countries, including the United States and Germany, ended in 1945.”
- Reference Answer: “World War II ended on September 2, 1945.”
The model’s response has low context precision because it includes excessive, irrelevant context.
- Context Recall
Context recall evaluates how comprehensively the model uses relevant information from the reference document to support its response. If important details are missing, recall will be low.
Contoh:
Prompt: “Name two ways enzymes work.”
- Reference Answer:
- “Enzymes speed up chemical reactions by lowering activation energy.”
- “Enzymes work specifically with certain substrates.”
- Model Response: “Enzymes work by lowering activation energy.”
The model’s response has low context recall because it covers only part of the relevant information.
The evaluation process is conducted using the following script:
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
from ragas import evaluate
import pandas
result = evaluate(
qa["eval"],
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result_df = result.to_pandas()
result_df[['faithfulness','answer_relevancy','context_precision', 'context_recall']].mean(axis=0)In this process:
- qa[“eval”] contains the dataset, which includes pairs of questions (queries), model-generated answers, and relevant document contexts.
- The evaluate function performs evaluation using the four metrics described earlier (Faithfulness, Answer Relevancy, Context Precision, and Context Recall).
- The evaluation results are stored in a dataframe format, facilitating further analysis. Using this dataframe, we calculate the average score for each metric to provide an overall view of the model’s performance.
- Output:
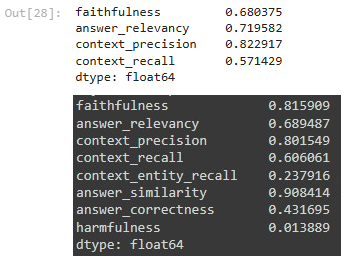
RAGAS produces measurable scores for RAG responses, making it one of the primary tools used in the initial stages of evaluation.
BERT: A Benchmark Model for Textual Analysis
BERT (Bidirectional Encoder Representations from Transformers) was employed in the experiments as a comparative model to measure semantic similarity between the RAG-generated responses and reference answers. Semantic similarity refers to the degree of alignment in meaning (rather than surface word forms) between two pieces of text, such as words, sentences, or paragraphs. BERT enables a more accurate analysis by understanding the context and meaning of the text deeply.
BERT serves as a robust evaluator for assessing the quality of RAG responses due to two main reasons:
- Ability to Understand Paraphrases
BERT excels at recognizing paraphrases—different sentences that convey the same meaning. Unlike traditional n-gram-based metrics that focus on word overlap, BERT calculates semantic similarity using cosine similarity in a contextualized manner. Example:- Reference: “Masyarakat Indonesia menyukai makanan lokal.”
- Response A: “Orang Indonesia cenderung menyukai hidangan tradisional.”
- Response B: “Orang Indonesia suka membuang makanan.”
- Response A is semantically more similar to the reference, whereas Response B is irrelevant.
- Ability to Capture Sentence Relationships: BERT differentiates meaning based on inter-phrase relationships, such as cause-effect. For example, “If it rains, the road gets wet.” has a different meaning from “The road is wet because of the rain.”. These sentences express similar semantics, but BERT can accurately capture their relationship.
Hugging Face’s transformers library, combined with the bert_score module, allows the evaluation of semantic similarity. Below is an example implementation:
from transformers import BertTokenizer, BertModel
from bert_score import BERTScorer
# Example texts
reference = "This is a reference text example."
candidate = "This is a candidate text example."
# BERTScore calculation
scorer = BERTScorer(model_type='bert-base-uncased')
P, R, F1 = scorer.score([candidate], [reference])
print(f"BERTScore Precision: {P.mean():.4f}, Recall: {R.mean():.4f}, F1: {F1.mean():.4f}")Conclusion
# Precision: 0.95, Recall: 0.96, F1: 0.96BERT measures three main metrics: precision, recall, and F1. Below is the explanation and the examples:
- Precision
Precision evaluates how many words in the response are relevant to the reference, without considering completeness.
- Example:
- Reference: “This is a reference text example.”
- Response A: “This is a text.”
- Response B: “This is a random text example with extra words.”
Response A has higher precision because all its words are relevant, whereas Response B includes irrelevant words like “random,” “with,” and “extra.”
- Recall
Recall measures the completeness of the response—how much information from the reference is captured in the response.
- Example:
- Reference: “This is a reference text example.”
- Response A: “This is a text.”
- Response B: “This is a random text example with extra words.”
Response B has higher recall because it covers more of the reference, even though it includes additional irrelevant words.
- F1-Score
F1-score balances precision and recall. If one metric is significantly lower, the F1-score will also be low.
- Example:
- Reference: “This is a reference text example.”
- Response A: “This is a text.”
- Response B: “This is a random text example with extra words.”
Response A has a higher F1-score because it is more accurate and relevant, even though it lacks completeness. Response B, while having high recall, suffers from low precision due to irrelevant words.
Levenshtein Distance: Measuring Character Differences
Levenshtein Distance is a metric used to measure how different two texts are based on the number of changes required to transform one text into the other. These changes consist of three types of operations:
- Insertion: Adding a character to the text.
- Deletion: Removing a character from the text.
- Substitution: Replacing one character with another.
This metric is often employed to evaluate the similarity between a model’s response and a reference answer, particularly in automated testing. The smaller the Levenshtein Distance, the more similar the response is to the reference.
Python Implementation Example:
from Levenshtein import distance
reference_text = "The sun set behind the mountains, casting a warm, orange glow across the horizon."
candidate_text = "As the mountains obscured the sun, a warm, orange glow painted the horizon."
levenshtein_dist = distance(reference_text, candidate_text)
print(f"Levenshtein Distance between {reference_text} & {candidate_text} is {str(levenshtein_dist)}")
# Levenshtein Distance between The sun set behind the mountains, casting a warm, orange glow across the horizon. & As the mountains obscured the sun, a warm, orange glow painted the horizon. is 38Interpretation:
- A value of 38 indicates that 38 edit operations (insertion, deletion, or substitution) are needed to transform the candidate text into the reference text.
- Lower Levenshtein Distance: The candidate text is closer to the reference and considered more accurate.
- Higher Levenshtein Distance: The candidate text diverges significantly from the reference, indicating a need for improvement.
Application in RAG Evaluation:
In the context of Retrieval-Augmented Generation (RAG) evaluation:
- Low values: Indicate that the model’s response is close to the reference and thus accurate.
- High values: Suggest the model’s response is far from the reference, signaling that the model’s output requires refinement.
Levenshtein Distance serves as a straightforward yet powerful tool for assessing textual similarity in RAG systems.
Inconsistencies in RAG Benchmarking Tools
At first glance, evaluation methods like RAGAS, BERTScore, and Levenshtein Distance seem capable of comparing RAG responses to reference answers automatically. But does this mean we’ve solved the RAG benchmarking problem? The answer is no.
While these methods are practical and produce seemingly convincing scores, my testing reveals that all three have fundamental weaknesses that make them unreliable. These automated evaluations often yield inconsistent results compared to manual evaluation, which remains the gold standard because it considers the context and meaning of answers comprehensively.
RAGAS Evaluation
RAGAS has several limitations that need to be addressed, making it less ideal as the sole evaluation tool for Retrieval-Augmented Generation (RAG) systems. Below is an analysis of a specific case illustrating RAGAS’s shortcomings:
Case Example
Question:
In the context of submitting a Debt Reduction Request Letter by a Debtor, what documents should be included, especially those related to financial statements and integrity declarations?
Agent’s Response:
To submit a Debt Reduction Request Letter, the debtor must follow the procedure and include documents as stipulated in the legal provisions. The required steps and documents include:
- Prepare the Application Document:
- Create a Debt Reduction Request Letter that includes the reasons for the request. The letter must follow the format outlined in Annex II of the institution’s regulation.
- Attach Supporting Documents:
- A notarized statement declaring:
- The debtor cannot financially meet their obligations in full within the liquidation timeframe.
- The debtor has not misused the loan.
- The debtor has not engaged in illegal activities that cause losses or jeopardize the bank’s continuity.
- An Anti-Bribery and Gratification Statement confirming that the debtor has not offered bribes or gratuities to the Liquidation Team.
- A notarized statement declaring:
- Provide Financial Data:
- Supporting data such as payslips, bank statements, financial reports, and information on owned assets.
- Submit the Application:
- Submit all documents to the Liquidation Team within a maximum of 30 days after the documents are prepared.
- Wait for Liquidation Team Evaluation:
- The Liquidation Team will evaluate the documents and provide a decision.
Metrics Answer Relevancy: 0.43064 (low relevancy score).
Case Analysis
- Overly Detailed Context
The question requests specific documents, including statements related to financial and integrity matters. The agent’s response already includes:
- A notarized statement.
- An anti-bribery and gratification statement.
However, the response also provides additional information, such as submission steps and a timeline, which RAGAS considers as mismatches. In reality, this additional information is relevant and provides a complete picture to the user.
- Failure to Assess Holistic Relevance
RAGAS evaluates relevancy based on textual similarity and the presence of specific elements in the reference answer. As a result:
- Useful additional information is considered noise.
- Responses with different structures or presentation styles receive low scores even if they are substantively relevant.
- Excess Information Treated as Mismatches
The agent’s response includes extra details such as:
- Document preparation steps.
- Submission timelines.
- Types of supporting financial data.
Although these details are useful, RAGAS categorizes them as “excess” that reduces answer relevancy. This highlights RAGAS’s inability to differentiate between helpful additional information and genuinely unnecessary details.
- Difficulty Capturing Nuances in Answers
The agent’s response covers the core elements of the reference answer but provides broader explanations. RAGAS, focused on literal similarity or the presence of specific phrases, fails to capture the holistic relevance of the answer. Consequently, valid responses are scored poorly.
The example above demonstrates RAGAS’s limitations in:
- Assessing the relevance of answers that include additional but contextually relevant information.
- Understanding nuances and the substance of responses comprehensively.
- Avoiding penalties for responses that offer more detailed explanations.
Thus, relying solely on RAGAS for evaluating RAG systems can lead to inaccurate assessments. Additional evaluation approaches are required to capture answer relevance more comprehensively, including the ability to understand the context and nuances of the responses.
BERTScore Evaluation
Berikut adalah salah satu contoh perbandingan hasil evaluasi manual dan otomatis menggunakan BERTScore:
Below is an example of comparing manual and automated evaluations using BERTScore:
- Question 1
Question:
In which article, in which section, in which chapter, and under which law is it stated that “The Deposit Insurance Corporation is responsible for the management and administration of assets and liabilities obtained or originating from the implementation of the Banking Restructuring Program”?
Reference Answer:
It is found in Article 40, Third Section on Banking Restructuring during a Financial System Crisis, in Chapter IV regarding handling a financial system crisis, under Law No. 9 of 2016.
Model’s Answer:
The explanation regarding the Deposit Insurance Corporation’s responsibility for managing and administering assets and liabilities derived from the implementation of the Banking Restructuring Program is in Article 41(1), located in the same section of the document. This article is in the same chapter and regulated under the Deposit Insurance Corporation Law.
- Manual Score: 0.4 (the answer is deemed incorrect due to significant deviation from the reference).
- BERT F1 Score: 0.728 (the automated score indicates the answer is reasonably close to the reference).
- Question 2
Question:
When did the Third Amendment to the Deposit Insurance Corporation Regulation No. 1/PLPS/2011 concerning Bank Liquidation (State Gazette of the Republic of Indonesia Year 2019 No. 982) take effect?
Reference Answer:
This regulation took effect on the date of promulgation, September 5, 2022.
Model’s Answer:
This regulation took effect on April 28, 2020, the date it was promulgated. This can be seen in Article 20 of the Deposit Insurance Corporation Regulation No. 1 of 2020, which states, “This regulation takes effect on the date of promulgation.”
- Manual Score: 0.1 (the answer is deemed incorrect due to significant deviation from the reference).
- BERT F1 Score: 0.83 (the automated score indicates the answer is reasonably close to the reference).
These results highlight inconsistencies. If we rely solely on the BERTScore, we might mistakenly assume the model’s responses are correct. However, the model’s answers deviate significantly from the reference answers.
Key Issues
- Inability to Accurately Reflect Semantic Proximity
BERTScore struggles to consistently evaluate the semantic closeness between a response and its reference.
Ambiguity in Threshold Determination
The difficulty in setting a definitive threshold score to judge whether an answer is correct or incorrect makes it unreliable for binary evaluation.
Levenshtein Distance Evaluation
Levenshtein Distance also has significant flaws. This method only measures the number of character changes between two texts without considering context or semantic meaning. As a result, texts with very different meanings can have a low distance score, while texts with similar meanings can have a high distance score.
Example:
reference_text = "The red fox jumps over a lazy dog"
candidate_text = "The red fox jumps over a lazy dog"
# Levenshtein Distance between The red fox jumps over a lazy dog & The red fox jumps over a lazy dog is 0
candidate_text = "The red dog runs over a lazy fox"
# Levenshtein Distance between The red fox jumps over a lazy dog & The red dog runs over a lazy fox is 7
candidate_text = "A reddish fox hops over a drowsy dog"
# Levenshtein Distance between The red fox jumps over a lazy dog & A reddish fox hops over a drowsy dog is 15In the example above, the third sentence has a meaning closer to the reference than the second sentence, but the Levenshtein Distance for the third sentence is larger (15) than the second sentence (7). This shows the method’s inability to capture semantic proximity, which is an important aspect in RAG evaluation.
Why Are the Results Inconsistent?
This inaccuracy occurs due to:
- Lack of Domain Knowledge: Automatic evaluation models do not always understand the specific context of the domain being tested, such as law, medicine, or culinary arts. As a result, valid responses in certain contexts are often given low scores.
- Limitations in Contextual Analysis: Methods like Levenshtein only measure character differences without understanding the meaning or intent of the text, while BERT can give high scores to responses that are semantically incorrect.
Giskard: A Superior Solution for AI Model Evaluation
Giskard is an automated model evaluation platform designed to support AI developers in ensuring that their systems are reliable, secure, and free from bias. Compared to other evaluation tools, Giskard stands out for its comprehensive approach and its ability to evaluate retrieval-augmented generation (RAG) pipelines in depth.
With Giskard, AI developers can not only identify potential errors or biases but also receive specific recommendations to improve each component within the pipeline. This provides greater confidence in the development of AI applications, especially in areas like customer service and decision-making.
Key Features of Giskard
Giskard has several standout features that make it a highly useful evaluation tool:
- Automated Testing
Giskard is capable of running various tests automatically without the need for constant supervision. This saves time for developers working with large-scale AI systems. - AI Risk Identification
The tool excels at detecting potential issues within AI models, such as biases that could affect the fairness of AI decisions. - Custom Test Creation
Giskard makes it easy for developers to create different types of tests tailored to their model’s specific needs, including for RAG pipelines. - Compatibility with Popular AI Tools
Giskard can be integrated with various commonly used AI development tools, making it easy for developers to incorporate it into their workflows. - Performance Evaluation
The platform is capable of measuring model performance in detail, ensuring that the model meets the desired quality standards. - Security Testing
Giskard provides specialized tests to ensure the security of AI systems, which is crucial for applications that impact human lives.
How Giskard Works?
The evaluation process with Giskard involves several key steps:
- Preparation and Integration
- The first step is to connect Giskard to the AI model that you want to test. This process is simple and quick to perform.
import giskard
import os
from giskard.llm.client.openai import OpenAIClient
giskard.llm.set_llm_api("openai")
oc = OpenAIClient(model="gpt-4")
giskard.llm.set_default_client(oc)
- Test Selection
- Giskard provides various types of tests, including performance measurement, bias detection, and security evaluation. Users can select the tests that are most relevant to their goals. For this case, performance measurement for RAG (RAG Evaluation Toolkit) is done.
- Creating Test Set
- The first task that Giskard can perform is to automatically create a test set. However, if automatic creation is not desired, the test set can be input manually.
- Example of implementing automatic test set creation in Giskard:
from giskard.rag import generate_testset
from giskard.rag.question_generators import simple_questions, complex_questions, situational_questions, double_questions
test_set = generate_testset(
knowledge_base,
num_questions = 50,
language='id',
question_generators=[simple_questions, complex_questions, situational_questions, double_questions],
agent_description = "A chatbot answering questions based on document, please formulate the question and answer in Bahasa Indonesia"
)
- Giskard can create several types of questions:
- Simple Questions: Simple questions generated from knowledge base excerpts. Example: “What is the capital of France?”
- Complex Questions: More complex questions created through paraphrasing. Example: “What is the name of the capital of Victor Hugo’s country?”
- Distracting Questions: Questions designed to confuse the RAG retrieval process with distracting elements from the knowledge base that are not relevant to the question. Example: “Italy is beautiful, but what is the capital of France?”
- Situational Questions: Questions that include user context to evaluate the model’s ability to generate relevant answers. Example: “I’m planning a trip to Europe, what is the capital of France?”
- Double Questions: Questions with two parts to evaluate the RAG query rewrite ability. Example: “What is the capital and population of France?”
- Conversational: Questions that are part of a conversation, where the first message explains the context of the question asked in the last message, also testing the rewriter. Example: “I want to know some information about France. What is its capital?”
- Running Evaluation and Generating Reports
- Running an evaluation using Giskard is straightforward, utilizing the functions provided in Python:
from giskard.rag import evaluate
# Wrap your RAG model
def get_answer_fn(question: str, history=None) -> str:
"""A function representing your RAG agent."""
# Format appropriately the history for your RAG agent
messages = history if history else []
messages.append({"role": "user", "content": question})
# Get the answer
answer = get_answer_from_agent(messages) # could be langchain, llama_index, etc.
return answer
# Run the evaluation and get a report
report = evaluate(get_answer_fn, testset=testset, knowledge_base=knowledge_base)- Analyzing Results
- Giskard presents the test results in detail, including performance metrics, potential issues, and improvement recommendations for each component in the pipeline.
- There are several metrics in Giskard to measure RAG performance:
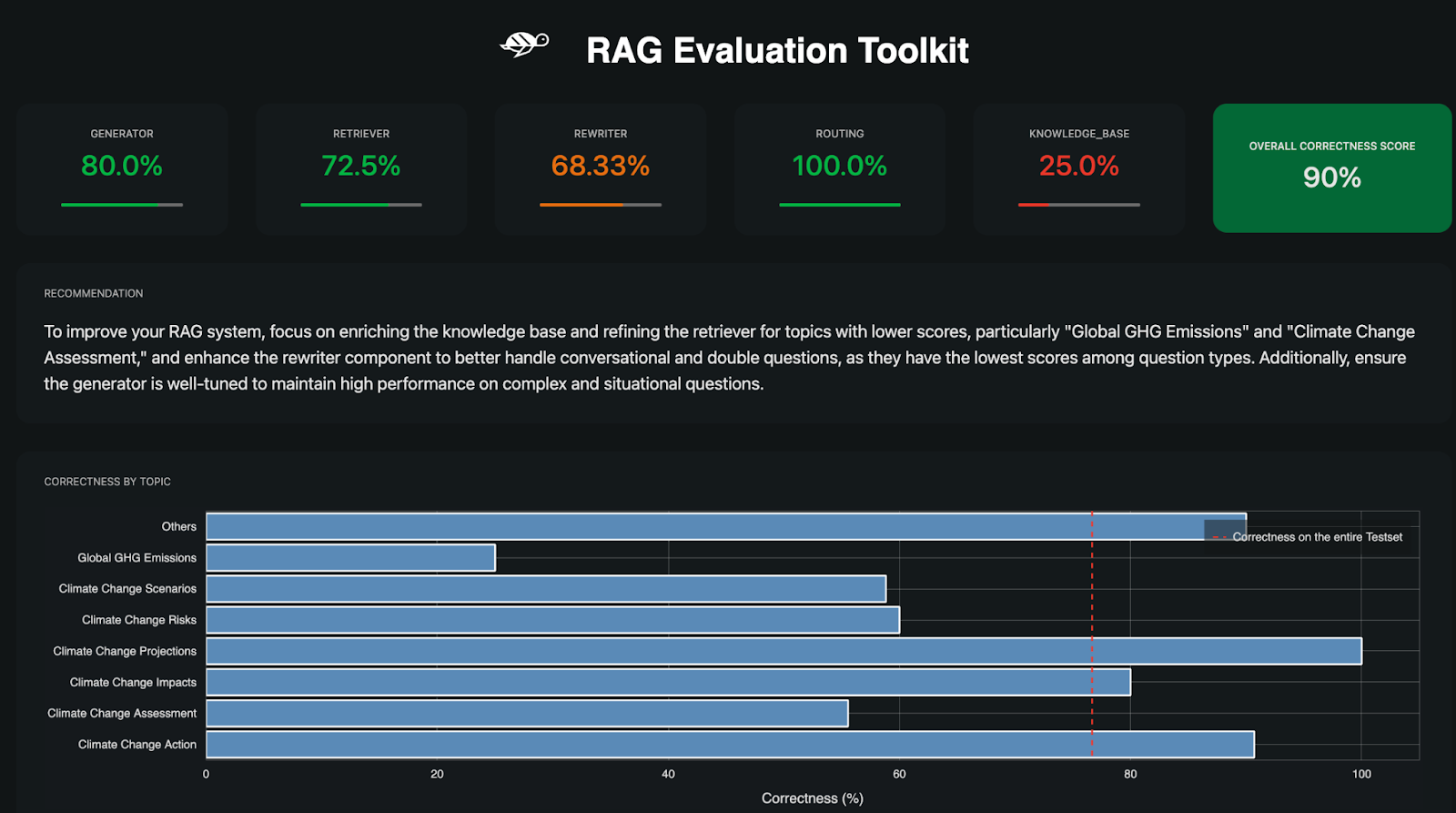
- Generator
- Generates responses from Large Language Models (LLMs).
- Giskard evaluates the quality of responses based on relevance, semantic alignment, and context accuracy.
- Retriever
- Retrieves relevant data from the knowledge base.
- Giskard measures the precision and coverage of the retriever to ensure the information provided is relevant to the query.
- Rewriter
- Modifies user queries to make them more relevant to the knowledge base.
- Giskard ensures the rewritten query still aligns with the user’s original intent.
- Routing
- Filters queries based on their intent and directs them to the appropriate path.
- Giskard evaluates the accuracy of routing in mapping the intent correctly.
- Knowledge Base
- External data source used to answer queries.
- Giskard validates the completeness and relevance of the data in the knowledge base.
- Example of implementing a knowledge base in Giskard:
from giskard.rag import KnowledgeBase
knowledge_base = KnowledgeBase(pd.DataFrame(d.page_content for d in document)) # In this case, is the content in the document we have made into dataframe
knowledge_base
- Improvements and Iteration
- Based on the results provided, developers can make improvements to the model. Afterward, Giskard is used again to ensure the improvements have been successfully applied.
Why is Giskard Superior?
Giskard has several advantages that address the fundamental weaknesses of automatic evaluation methods such as RAGAS, BERTScore, and Levenshtein Distance. Here are the reasons why Giskard is a more reliable choice for evaluating Retrieval-Augmented Generation (RAG) systems:
- Ability to Automatically Generate Test Sets
Giskard is equipped with a feature to automatically generate test sets, which is extremely helpful for benchmarking at scale. This saves time and effort, especially when a large or variable amount of test data is required. In this way, testing can be done faster and more efficiently without compromising quality.
- More Consistent and Accurate Results
Giskard proves its superiority by providing consistent and accurate evaluation results compared to other benchmarking tools. Consistency here means that the evaluation scores produced by Giskard align with manual evaluation results, demonstrating the reliability of the tool in assessing model performance objectively.
For example, I evaluated two RAG pipelines using different LLMs as generators: OpenAI GPT-4 and Llama 3 8B. The test results showed close scores for both models, affirming the consistency of Giskard’s evaluation. To verify further, I compared the automatic results from Giskard with manual evaluation. Giskard’s automatic score of 78% matched the manual evaluation, indicating high accuracy and minimal bias in testing.
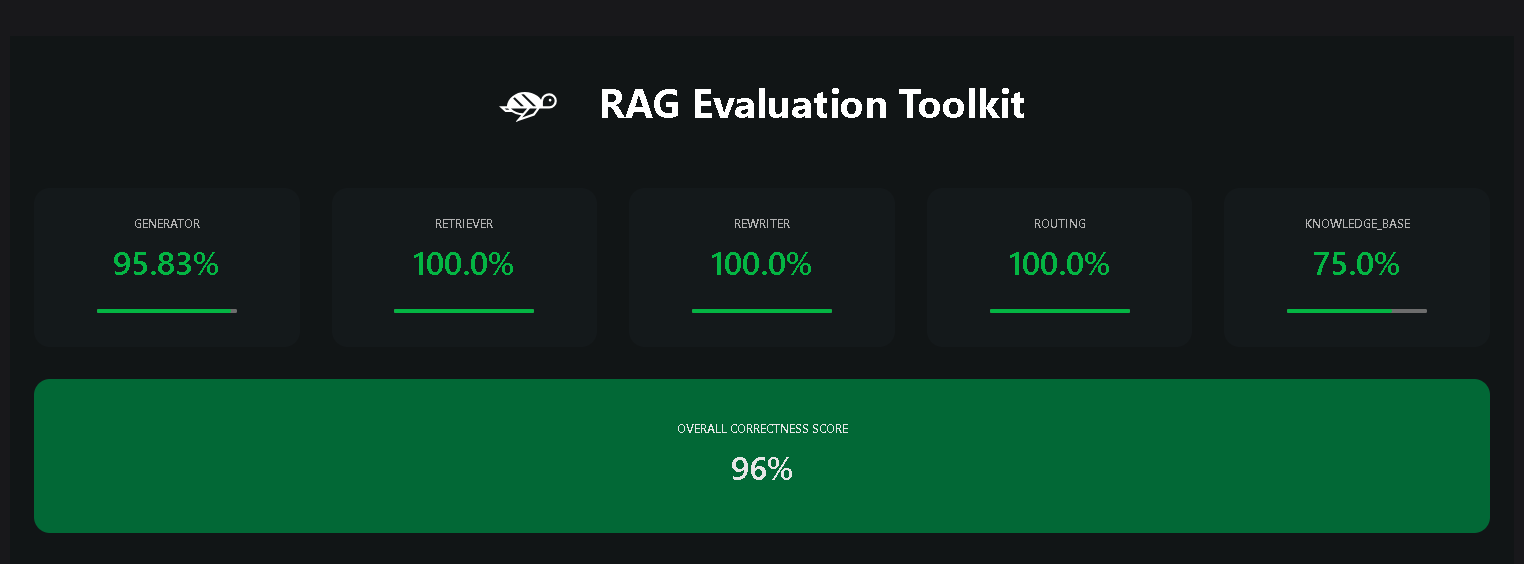

Giskard Test Results (Llama 3 8B)
The reliability of these results makes me even more confident that Giskard is the right tool to elevate my RAG pipeline development to the next level. This tool enables in-depth and efficient testing without sacrificing quality, providing additional confidence in ensuring optimal model performance.
Unlike RAGAS, which often fails to capture the nuances of context in evaluating answers, Giskard is able to assess responses based on the specific context of the query and the retrieved documents. In the same case example used in RAGAS, Giskard’s result for this case is TRUE (Correctness), meaning that Giskard evaluates the agent’s answer as correct because it successfully includes the requested document and provides additional relevant information to give context to the user. Giskard does not only assess answer relevance based on text similarity, but also considers the value of additional relevant information. In this case, information such as the application steps, timeline, and types of supporting data are seen as essential to providing a comprehensive picture for the user. Giskard is not just focused on literal similarity or specific phrases, but also on the substance of the answer. This allows Giskard to capture the nuances of the response, including when the agent provides a broader explanation but still remains contextually appropriate.
- End-to-End Comprehensive Evaluation
Giskard supports holistic evaluation of RAG systems, including both the retrieval and generative components. By analyzing performance at each step in the pipeline, Giskard can identify weak points, whether the issue stems from the retrieval process (choosing irrelevant documents) or the generation process (inaccurate answers). This end-to-end evaluation provides a more complete picture compared to RAGAS, which focuses only on the quality of the final answer.
- Consistent Semantic Proximity Reflection
One weakness of BERTScore and Levenshtein Distance is inconsistency in measuring the semantic proximity between the model’s answer and the reference answer.
- BERTScore often gives high scores for answers that are not fully semantically relevant.
- Levenshtein Distance, on the other hand, only looks at character differences without considering the meaning of the text.
Giskard addresses this weakness with advanced algorithms that ensure semantic proximity is evaluated consistently. This allows Giskard to provide scores that better reflect the true meaning of the answer.
- Domain Knowledge Support
Giskard is designed to understand specific domain knowledge such as law, medicine, or finance. With this capability, Giskard can evaluate responses more accurately according to the terminology and context specific to each domain. This makes it superior to other methods that often fail in domain-specific scenarios.
With its combination of the ability to understand context, evaluate the entire RAG pipeline, and reflect semantic proximity consistently, Giskard becomes a more reliable and superior solution for benchmarking RAG systems.
Conclusion
Based on my experience, Giskard is the best tool for benchmarking RAG compared to RAGAS, BERTScore, and Levenshtein Distance. Its strengths lie in its ability to provide consistent, accurate results that align with manual evaluation. Furthermore, Giskard allows for comprehensive testing of every component in the RAG pipeline and offers clear feedback for further improvement. With advanced features such as automated test set creation and performance evaluation without bias, Giskard is a reliable and efficient solution.
My journey of experimenting with various benchmarking tools, such as RAGAS, BERTScore, and Levenshtein Distance, has taught me valuable lessons about the weaknesses and inconsistencies of each method. This experience has only strengthened my conviction that Giskard is the most suitable tool for conducting in-depth RAG evaluation.
For readers who want to try benchmarking tools, my advice is to first understand the specific needs of the RAG pipeline you wish to evaluate. If you’re looking for a tool that provides precise, reliable results and supports holistic model development, Giskard is definitely worth considering. Don’t hesitate to explore its features and integrate it into your workflow. My experience shows that Giskard is not just an evaluation tool but also a partner in ensuring the success of your RAG model.

0 Comments
Leave A Comment