
Retrieval-Augmented Generation (RAG) adalah metode inovatif yang menggabungkan kemampuan retrieval dengan model generatif untuk menghasilkan respons yang lebih akurat dan relevan. Dengan memanfaatkan sumber data eksternal, RAG mampu mengatasi keterbatasan yang sering ditemui pada Large Language Model (LLM), seperti informasi yang sudah usang dan risiko halusinasi (misinformation). Selain itu, keunggulan lain dari RAG adalah kemampuannya untuk dilatih menggunakan proprietary information tanpa risiko informasi tersebut bocor ke vendor LLM, sehingga menjaga kerahasiaan data perusahaan.
Namun, bagaimana kita bisa memastikan bahwa RAG benar-benar mampu mengatasi tantangan ini? Terlebih lagi, dalam kasus di mana RAG digunakan dengan dokumen-dokumen berbasis regulasi yang jumlahnya sangat banyak, proses evaluasi menjadi semakin kompleks. Tantangan utamanya adalah sulitnya melakukan benchmarking manual secara efisien, terutama jika para penguji manual tidak memiliki domain knowledge yang mendalam terhadap dokumen-dokumen tersebut. Di sinilah pentingnya otomatisasi dalam proses benchmarking, untuk memastikan evaluasi yang konsisten, cepat, dan tetap akurat.
Benchmarking adalah proses evaluasi berbasis metrik terukur untuk menilai kualitas dan keandalan respons yang dihasilkan oleh RAG. Dalam artikel ini, saya akan berbagi perjalanan dalam menemukan pendekatan benchmarking yang optimal untuk RAG. Proses ini tidak mudah—penuh tantangan dalam menjaga keseimbangan antara kontrol kualitas dan efisiensi waktu. Pada akhirnya, perjalanan ini membawa saya kepada tools benchmarking yang saya yakini sebagai yang terbaik: Giskard.
Perjalanan Benchmarking untuk Evaluasi RAG
Tahap Awal: Membuat Test Set Secara Manual untuk Kualitas Optimal
Langkah pertama dalam benchmarking adalah membuat test set sebagai standar evaluasi. Testset ini dibuat secara manual dengan mengambil sampel pertanyaan dari berbagai topik yang relevan berdasarkan proprietary information yang akan digunakan untuk mentraining RAG. Dalam contoh ini kami menggunakan 12 dokumen Peraturan Lembaga Penjamin Simpanan (PLPS). Proses pengambilan dilakukan secara heuristik, dengan memilih 8-10 pertanyaan secara acak (random sampling) dari setiap dokumen.
Pendekatan manual ini dipilih karena memberikan kontrol penuh terhadap kualitas test set. Setiap elemen dapat dipastikan relevan dan mendukung evaluasi RAG secara tepat. Meskipun memakan waktu, langkah ini membantu menghindari bias atau kesalahan yang mungkin terjadi jika menggunakan metode otomatis.
Pengujian Manual: Langkah Awal Evaluasi Akurat
Setelah test set dibuat, pertanyaan dari test set diajukan ke sistem RAG, dan respons model dibandingkan secara manual dengan referensi dokumen. Pendekatan manual ini memastikan setiap jawaban dinilai berdasarkan relevansi dan koherensi dengan dokumen sumber. Hasil pengujian manual menjadi benchmark awal yang penting, memberikan pemahaman mendalam tentang kekuatan dan kelemahan model RAG.
Tantangan Skalabilitas: Kebutuhan untuk Otomatisasi
Meskipun pendekatan manual efektif untuk evaluasi berskala kecil, tantangan muncul saat skala evaluasi meningkat. Otomatisasi diperlukan untuk menghemat waktu dan tenaga tanpa mengorbankan kualitas evaluasi. Namun, otomatisasi ini harus tetap menjaga standar akurasi yang telah ditetapkan dalam pengujian manual.
Eksplorasi Tools untuk Benchmarking RAG
RAGAS: Standar Evaluasi untuk RAG
RAGAS (Retrieval-Augmented Generation Assessment System) adalah framework evaluasi yang menyediakan berbagai metrik untuk mengukur kualitas respons model RAG. Berikut penjelasan mengenai metrik beserta contoh penggunaannya:
- Faithfulness (Kebenaran Jawaban)
Faithfulness mengukur sejauh mana jawaban yang diberikan oleh model didukung oleh informasi dalam dokumen referensi. Jawaban harus konsisten dengan sumber atau dokumen acuan tanpa menambahkan informasi yang tidak ada.
Contoh:
Prompt: “Kapan Perang Dunia II berakhir?”- Jawaban Model: “1939.”
- Referensi Jawaban: “Perang Dunia II berakhir pada 2 September 1945.”
Jawaban model memiliki faithfulness rendah karena tidak sesuai dengan fakta dalam dokumen referensi.
- Answer Relevancy (Relevansi Jawaban)
Answer relevancy menilai apakah jawaban yang diberikan model relevan dengan pertanyaan, meskipun mungkin tidak sepenuhnya akurat atau mendetail. Metrik ini mengukur keterkaitan jawaban dengan konteks pertanyaan.
Contoh:
Prompt: “Kapan Perang Dunia II berakhir?”- Jawaban Model: “Pada tahun 1945.”
- Referensi Jawaban: “Perang Dunia II berakhir pada 2 September 1945.”
Jawaban model memiliki answer relevancy tinggi karena relevan dengan pertanyaan meskipun kurang spesifik.
- Context Precision (Presisi Konteks)
Context precision mengukur seberapa tepat dan relevan bagian dokumen yang diambil oleh model untuk menghasilkan jawaban. Semakin relevan konteks yang digunakan, semakin tinggi precision-nya.
Contoh:
Prompt: “Kapan Perang Dunia II berakhir?”- Jawaban Model: “Perang Dunia II yang merupakan konflik global yang melibatkan banyak negara, termasuk Amerika Serikat dan Jerman, berakhir pada 1945.”
- Referensi Jawaban: “Perang Dunia II berakhir pada 2 September 1945.”
Jawaban model memiliki context precision rendah karena menyertakan konteks berlebihan yang tidak relevan.
- Context Recall (Cakupan Konteks)
Context recall mengukur seberapa lengkap model menggunakan informasi relevan dari dokumen referensi untuk mendukung jawabannya. Jika model kehilangan informasi penting, maka recall akan rendah.
Contoh:
Prompt: “Sebutkan dua cara kerja enzim.”- Referensi Jawaban:
- “Enzim mempercepat reaksi kimia dengan menurunkan energi aktivasi.”
- “Enzim bekerja secara spesifik terhadap substrat tertentu.”
- Jawaban Model: “Enzim bekerja dengan menurunkan energi aktivasi.”
Jawaban model memiliki context recall rendah karena hanya mencakup sebagian dari informasi yang relevan.
- Referensi Jawaban:
Proses evaluasi menggunakan RAGAS dilakukan dengan script berikut:
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
from ragas import evaluate
import pandas
result = evaluate(
qa["eval"],
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result_df = result.to_pandas()
result_df[['faithfulness','answer_relevancy','context_precision', 'context_recall']].mean(axis=0)Di sini:
- qa[“eval”] adalah data yang berisi pasangan pertanyaan (query), jawaban yang dihasilkan oleh model, dan konteks dokumen yang relevan.
- Fungsi evaluate menjalankan evaluasi dengan keempat metrik yang telah disebutkan sebelumnya.
- Hasil evaluasi disimpan dalam format dataframe untuk memudahkan analisis lebih lanjut. Dengan menggunakan dataframe ini, kami menghitung nilai rata-rata dari masing-masing metrik untuk mendapatkan gambaran umum performa model.
- Contoh output yang dihasilkan:
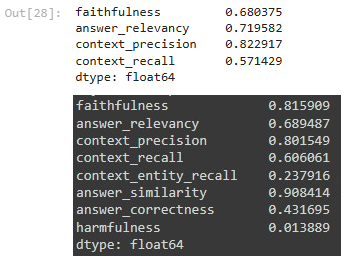
RAGAS memberikan skor terukur untuk respons RAG, menjadikannya salah satu tools utama yang digunakan dalam evaluasi awal.
BERT: Model Pembanding untuk Analisis Tekstual
BERT (Bidirectional Encoder Representations from Transformers) digunakan dalam eksperimen sebagai model pembanding untuk mengukur semantic similarity (kesamaan semantik) antara respons yang dihasilkan RAG dan jawaban referensi. Semantic similarity adalah ukuran seberapa mirip makna (bukan hanya bentuk kata) antara dua teks, seperti kata, kalimat, atau paragraf. Dengan BERT, analisis ini menjadi lebih akurat karena mampu memahami konteks dan makna dari teks secara mendalam.
BERT memungkinkan kita untuk menilai kualitas respons RAG dalam menghasilkan jawaban yang koheren dan relevan. Dua alasan utama penggunaan BERT adalah:
- Kemampuan Memahami Parafrase
BERT unggul dalam mengenali parafrase, yaitu kalimat berbeda yang memiliki makna serupa. Berbeda dengan metrik tradisional berbasis n-gram yang hanya membandingkan kesamaan kata tanpa memahami konteks, BERT menghitung kesamaan semantik menggunakan cosine similarity.- Contoh:
- Referensi: “Masyarakat Indonesia menyukai makanan lokal.”
- Respons A: “Orang Indonesia cenderung menyukai hidangan tradisional.”
- Respons B: “Orang Indonesia suka membuang makanan.”
Respons A dianggap lebih mirip secara semantik karena maknanya sesuai dengan referensi, sedangkan Respons B tidak relevan.
- Contoh:
- Kemampuan Menangkap Hubungan dalam Kalimat
BERT mampu membedakan makna berdasarkan hubungan antarfrasa, seperti sebab-akibat. Misalnya, kalimat “Jika hujan, maka jalanan menjadi basah” memiliki makna berbeda dari “Jalanan basah karena hujan”. Hal ini memungkinkan BERT memberikan penilaian kesamaan yang lebih akurat.
Untuk menggunakan BERT dalam evaluasi kesamaan semantik, library transformers dari Hugging Face dapat digunakan bersama modul bert_score. Berikut adalah contohnya:
from transformers import BertTokenizer, BertModel
from bert_score import BERTScorer
# Example texts
reference = "This is a reference text example."
candidate = "This is a candidate text example."
# BERTScore calculation
scorer = BERTScorer(model_type='bert-base-uncased')
P, R, F1 = scorer.score([candidate], [reference])
print(f"BERTScore Precision: {P.mean():.4f}, Recall: {R.mean():.4f}, F1: {F1.mean():.4f}")Conclusion
# Precision: 0.95, Recall: 0.96, F1: 0.96BERT mengukur tiga metrik utama: precision, recall, dan F1. Berikut penjelasan dan contohnya:
- Precision
Precision mengukur seberapa banyak kata dalam respons yang relevan dengan referensi, tanpa mempertimbangkan kelengkapan informasi.- Contoh:
- Referensi: “This is a reference text example.”
- Respons A: “This is a text.”
- Respons B: “This is a random text example with extra words.”
Respons A memiliki precision lebih tinggi karena semua katanya relevan, sementara Respons B memiliki kata-kata tambahan yang tidak relevan, seperti “random”, “with”, “extra”.
- Contoh:
- Recall
Recall mengukur kelengkapan respons, yaitu seberapa banyak informasi dalam referensi yang tercakup dalam respons.- Contoh:
- Referensi: “This is a reference text example.”
- Respons A: “This is a text.”
- Respons B: “This is a random text example with extra words.”
Respons B memiliki recall lebih tinggi karena mencakup lebih banyak kata dari referensi meskipun memiliki tambahan kata tidak relevan.
- Contoh:
- F1-Score
F1-score adalah keseimbangan antara precision dan recall. Jika salah satu metrik terlalu rendah, maka skor F1 juga akan rendah.- Contoh:
- Referensi: “This is a reference text example.”
- Respons A: “This is a text.”
- Respons B: “This is a random text example with extra words.”
Respons A memiliki F1-score lebih tinggi karena lebih akurat dan relevan meskipun kurang lengkap, sedangkan Respons B memiliki recall tinggi tetapi precision rendah karena kata tambahan yang tidak relevan.
- Contoh:
Levenshtein Distance: Mengukur Perbedaan Karakter
Levenshtein Distance adalah metrik yang digunakan untuk mengukur seberapa berbeda dua teks berdasarkan jumlah perubahan yang diperlukan untuk mengubah satu teks menjadi teks lain. Perubahan ini meliputi tiga jenis operasi:
- Penyisipan (insertion): Menambahkan satu karakter ke dalam teks.
- Penghapusan (deletion): Menghapus satu karakter dari teks.
- Substitusi (substitution): Mengganti satu karakter dengan karakter lain.
Metrik ini sering digunakan untuk mengevaluasi kesesuaian antara respons model dan referensi jawaban, terutama dalam pengujian otomatis. Semakin kecil nilai Levenshtein Distance, semakin mirip respons dengan referensi.
Contoh implementasi Levenshtein Distance dalam Python:
from Levenshtein import distance
reference_text = "The sun set behind the mountains, casting a warm, orange glow across the horizon."
candidate_text = "As the mountains obscured the sun, a warm, orange glow painted the horizon."
levenshtein_dist = distance(reference_text, candidate_text)
print(f"Levenshtein Distance between {reference_text} & {candidate_text} is {str(levenshtein_dist)}")
# Levenshtein Distance between The sun set behind the mountains, casting a warm, orange glow across the horizon. & As the mountains obscured the sun, a warm, orange glow painted the horizon. is 38Nilai 38 yang didapat menunjukkan bahwa ada 38 operasi edit (penyisipan, penghapusan, atau substitusi) yang diperlukan untuk mengubah teks kandidat menjadi teks referensi.
Semakin kecil nilai Levenshtein Distance, semakin mirip teks kandidat dengan referensi. Jika nilainya 0, artinya teks kandidat dan referensi identik.
Dalam konteks evaluasi RAG (Retrieval-Augmented Generation), Levenshtein Distance digunakan untuk menilai sejauh mana respons model mendekati referensi jawaban.
- Jika nilai rendah: Respons model mendekati referensi dan dianggap akurat.
- Jika nilai tinggi: Respons model jauh dari referensi, yang menunjukkan bahwa jawaban model perlu diperbaiki.
Ketidakkonsistenan Tools Benchmarking RAG
Sekilas, metode evaluasi seperti RAGAS, BERTScore, dan Levenshtein Distance terlihat mampu membandingkan respons RAG dengan referensi jawaban secara otomatis. Namun, apakah itu berarti kita telah memecahkan masalah benchmark RAG? Jawabannya adalah belum.
Meskipun metode-metode ini praktis dan menghasilkan skor yang tampak meyakinkan, hasil pengujian saya menunjukkan bahwa ketiganya memiliki kelemahan mendasar yang membuat mereka kurang dapat diandalkan. Evaluasi otomatis ini sering kali memberikan hasil yang inkonsisten jika dibandingkan dengan evaluasi manual, yang merupakan standar emas karena dilakukan dengan mempertimbangkan konteks dan makna jawaban secara menyeluruh.
Evaluasi RAGAS
RAGAS memiliki beberapa kekurangan yang perlu diperhatikan, sehingga mungkin tidak ideal jika dijadikan satu-satunya alat evaluasi untuk sistem Retrieval-Augmented Generation (RAG). Berikut adalah analisis salah satu contoh kasus yang menunjukkan keterbatasan RAGAS:
Contoh Kasus
Pertanyaan: Dalam konteks pengajuan surat permohonan Potongan Utang oleh Debitur, dokumen apa saja yang harus disertakan, termasuk pernyataan terkait keuangan dan integritas?
Jawaban Agen: Untuk mengajukan surat permohonan Potongan Utang, Debitur harus mengikuti prosedur dan menyertakan dokumen yang ditentukan dalam ketentuan hukum. Berikut langkah-langkah dan dokumen yang perlu disertakan:
- Persiapkan Dokumen Permohonan:
- Buat surat permohonan Potongan Utang yang disertai dengan alasan mengapa permohonan diajukan. Surat harus mengikuti format yang tercantum dalam Lampiran II dari peraturan Lembaga.
- Lampirkan Dokumen Pendukung:
- Surat Pernyataan Bermeterai yang menyatakan bahwa:
- Debitur tidak mampu secara finansial untuk membayar kewajibannya secara penuh dalam jangka waktu likuidasi.
- Debitur tidak menyalahgunakan pinjaman.
- Debitur tidak melakukan perbuatan melanggar hukum yang mengakibatkan kerugian atau membahayakan kelangsungan usaha Bank.
- Surat Pernyataan Anti Penyuapan dan Gratifikasi, yang menyatakan bahwa Debitur tidak memberikan suap atau gratifikasi kepada Tim Likuidasi.
- Surat Pernyataan Bermeterai yang menyatakan bahwa:
- Pengumpulan Data Keuangan:
- Data pendukung seperti slip gaji, rekening koran, laporan keuangan, dan informasi aset yang dimiliki.
- Pengajuan Permohonan:
- Ajukan seluruh dokumen ke Tim Likuidasi dalam waktu maksimal 30 hari setelah dokumen disiapkan.
- Menunggu Evaluasi dari Tim Likuidasi:
- Tim Likuidasi akan mengevaluasi dokumen dan memberikan keputusan.
Metrics Answer Relevancy: 0.43064 (nilai relevansi rendah).
Analisa Kasus
1. Konteks yang Terlalu Detail
Pertanyaan meminta dokumen spesifik yang harus dilampirkan, termasuk pernyataan terkait keuangan dan integritas. Jawaban agen sebenarnya sudah mencakup:
- Surat pernyataan bermeterai.
- Surat pernyataan anti penyuapan dan gratifikasi.
Namun, jawaban agen juga memberikan informasi tambahan seperti langkah-langkah proses pengajuan dan timeline, yang dianggap RAGAS sebagai ketidaksesuaian. Padahal, informasi tambahan ini relevan dalam memberikan gambaran lengkap kepada pengguna.
2. Kegagalan Menilai Relevansi Secara Holistik
RAGAS menilai relevansi berdasarkan kemiripan teks (textual similarity) dan keberadaan elemen-elemen tertentu dari jawaban referensi. Akibatnya:
- Informasi tambahan yang berguna dianggap sebagai noise.
- Jawaban dengan struktur atau gaya penyampaian berbeda mendapat skor rendah meskipun relevan secara substansi.
3. Kelebihan Informasi Dianggap Ketidaksesuaian
Jawaban agen memberikan penjelasan tambahan seperti:
- Proses persiapan dokumen.
- Timeline pengajuan.
- Jenis data pendukung.
Meskipun informasi ini berguna, RAGAS menganggapnya sebagai “kelebihan” yang mengurangi relevansi jawaban. Hal ini menunjukkan bahwa RAGAS belum mampu membedakan antara informasi tambahan yang relevan dan yang benar-benar tidak diperlukan.
4. Kesulitan Memahami Nuansa Jawaban
Jawaban agen sebenarnya mencakup inti dari jawaban referensi, tetapi dengan penjelasan yang lebih luas. RAGAS, yang fokus pada kesamaan literal atau keberadaan frasa tertentu, gagal menangkap relevansi jawaban secara menyeluruh. Akibatnya, jawaban yang valid dinilai rendah.
Kesimpulan yang dapat diambil dari kasus di atas adalah RAGAS memiliki keterbatasan dalam:
- Menilai relevansi jawaban yang mencakup informasi tambahan tetapi tetap relevan secara konteks.
- Memahami nuansa dan substansi jawaban secara holistik.
- Menghindari penalti pada jawaban yang memberikan penjelasan lebih detail.
Oleh karena itu, penggunaan RAGAS sebagai satu-satunya alat evaluasi untuk sistem RAG dapat menghasilkan penilaian yang tidak akurat. Diperlukan pendekatan evaluasi tambahan yang mampu menangkap relevansi jawaban secara lebih komprehensif, termasuk kemampuan untuk memahami konteks dan nuansa jawaban.
Evaluasi BERTScore
Berikut adalah salah satu contoh perbandingan hasil evaluasi manual dan otomatis menggunakan BERTScore:
- Pertanyaan 1
Pertanyaan : Pada pasal berapa, terletak di bagian berapa, bab berapa, dan undang-undang nomor berapa yang menyebutkan bahwa ” Lembaga Penjamin Simpanan bertanggung jawab atas pengelolaan serta penatausahaan aset dan kewajiban yang diperoleh atau berasal dari penyelenggaraan Program Restrukturisasi Perbankan”?
Jawaban Referensi : Terletak pada pasal 40, bagian ketiga mengenai Restrukturisasi Perbankan dalam Krisis Sistem Keuangan pada bab IV mengenai penanganan krisis sistem keuangan, undang-undang nomor 9 tahun 2016.
Jawaban Model : Penjelasan mengenai tanggung jawab Lembaga Penjamin Simpanan atas pengelolaan dan penatausahaan aset dan kewajiban yang berasal dari penyelenggaraan Program Restrukturisasi Perbankan terdapat pada Pasal 41 ayat (1) yang terletak di bagian yang sama dari dokumen tersebut. Pasal ini terdapat dalam bab yang sama dan diatur oleh Undang-Undang mengenai Lembaga Penjamin Simpanan.
- Manual Score: 0.4 (jawaban dinilai salah karena jauh dari referensi).
- BERT F1 Score: 0.728 (skor otomatis menyatakan jawaban cukup dekat dengan referensi).
- Pertanyaan 2
Pertanyaan : Kapan Peraturan Lembaga mengenai Perubahan Ketiga atas Peraturan Lembaga Penjamin Simpanan Nomor 1/PLPS/2011 tentang Likuidasi Bank (Berita Negara Republik Indonesia Tahun 2019 Nomor 982), mulai berlaku?
Jawaban Referensi : Peraturan Lembaga ini mulai berlaku pada tanggal diundangkan, yaitu pada tanggal 5 September 2022.
Jawaban Model : Peraturan Lembaga ini mulai berlaku pada tanggal 28 April 2020, yang merupakan tanggal diundangkannya peraturan tersebut. Hal ini dapat dilihat pada Pasal 20 dari Peraturan Lembaga Penjamin Simpanan Nomor 1 Tahun 2020 yang menyatakan bahwa “Peraturan Lembaga ini mulai berlaku pada tanggal diundangkan.”
- Manual Score: 0.1 (jawaban dinilai salah karena jauh dari referensi).
- BERT F1 Score: 0.83 (skor otomatis menyatakan jawaban cukup dekat dengan referensi).
Hasil ini menunjukkan inkonsistensi. Jika hanya melihat skor BERT, kita mungkin mengira bahwa respons model pada pertanyaan yang kita ajukan sudah benar, akan tetapi jawaban model tersebut berbeda jauh dari jawaban referensi.
Masalah utama di sini adalah ketidakmampuan BERT untuk secara konsisten merefleksikan kedekatan semantik antara respons dan referensi. Dengan demikian, sulit untuk menentukan skor tertentu sebagai ambang batas (threshold) untuk menilai apakah jawaban benar atau salah.
Evaluasi Levenshtein Distance
Levenshtein Distance juga memiliki celah besar. Metode ini hanya mengukur jumlah perubahan karakter antara dua teks tanpa mempertimbangkan konteks atau makna semantik. Akibatnya, teks dengan makna yang sangat berbeda dapat memiliki nilai jarak yang rendah, sementara teks dengan makna serupa dapat memiliki nilai jarak yang tinggi.
Contoh Kasus:
reference_text = "The red fox jumps over a lazy dog"
candidate_text = "The red fox jumps over a lazy dog"
# Levenshtein Distance between The red fox jumps over a lazy dog & The red fox jumps over a lazy dog is 0
candidate_text = "The red dog runs over a lazy fox"
# Levenshtein Distance between The red fox jumps over a lazy dog & The red dog runs over a lazy fox is 7
candidate_text = "A reddish fox hops over a drowsy dog"
# Levenshtein Distance between The red fox jumps over a lazy dog & A reddish fox hops over a drowsy dog is 15Pada contoh di atas, kalimat ketiga memiliki makna yang lebih dekat dengan referensi dibandingkan kalimat kedua, namun Levenshtein Distance untuk kalimat ketiga lebih besar (15) daripada kalimat kedua (7). Hal ini menunjukkan ketidakmampuan metode untuk menangkap kedekatan semantik, yang merupakan aspek penting dalam evaluasi RAG.
Mengapa Hasil Tidak Konsisten?
Ketidakakuratan ini terjadi karena:
- Kurangnya Pengetahuan Domain:
Model evaluasi otomatis tidak selalu memahami konteks spesifik dari domain yang diuji, seperti hukum, medis, atau kuliner. Akibatnya, respons yang valid dalam konteks tertentu sering diberi skor rendah. - Keterbatasan pada Analisis Kontekstual:
Metode seperti Levenshtein hanya mengukur perbedaan karakter tanpa memahami arti atau tujuan teks, sedangkan BERT dapat memberikan skor tinggi pada respons yang secara semantik tidak tepat.
Giskard: Solusi Unggul untuk Evaluasi Model AI
Giskard adalah platform otomatisasi evaluasi model yang dirancang untuk mendukung pengembang AI dalam memastikan sistem mereka andal, aman, dan bebas dari bias. Dibandingkan dengan alat evaluasi lainnya, Giskard menonjol karena pendekatannya yang komprehensif dan kemampuannya untuk mengevaluasi pipeline retrieval-augmented generation (RAG) secara mendalam.
Dengan Giskard, developer AI tidak hanya dapat mengidentifikasi potensi kesalahan atau bias, tetapi juga menerima rekomendasi yang spesifik untuk memperbaiki setiap komponen dalam pipeline. Hal ini memberikan kepercayaan diri yang lebih besar dalam pengembangan aplikasi AI, terutama dalam bidang layanan pelanggan dan pengambilan keputusan.
Fitur Utama Giskard
Giskard memiliki beberapa fitur unggulan yang membuatnya menjadi alat evaluasi yang sangat berguna:
- Pengujian Otomatis
- Giskard mampu menjalankan berbagai pengujian secara otomatis tanpa memerlukan pengawasan terus-menerus. Hal ini menghemat waktu bagi pengembang yang bekerja dengan sistem AI skala besar.
- Identifikasi Risiko AI
- Alat ini unggul dalam mendeteksi potensi masalah dalam model AI, seperti bias yang dapat mempengaruhi keadilan keputusan AI.
- Pembuatan Tes Kustom
- Giskard memudahkan pengembang untuk membuat berbagai jenis tes sesuai dengan kebutuhan spesifik model mereka, termasuk untuk pipeline RAG.
- Kompatibilitas dengan Alat AI Populer
- Giskard dapat diintegrasikan dengan berbagai alat pengembangan AI yang umum digunakan, memudahkan pengembang untuk memasukkannya ke dalam alur kerja mereka.
- Evaluasi Kinerja
- Platform ini mampu mengukur performa model secara rinci, memastikan model memenuhi standar kualitas yang diinginkan.
- Tes Keamanan
- Giskard menyediakan tes khusus untuk memastikan keamanan sistem AI, yang sangat penting untuk aplikasi yang memengaruhi kehidupan manusia.
Cara Kerja Giskard Secara Praktis
Proses evaluasi dengan Giskard mencakup beberapa langkah utama:
- Persiapan dan Integrasi
- Langkah pertama adalah menghubungkan Giskard dengan model AI yang ingin diuji. Proses ini sederhana dan cepat dilakukan.
import giskard
import os
from giskard.llm.client.openai import OpenAIClient
giskard.llm.set_llm_api("openai")
oc = OpenAIClient(model="gpt-4")
giskard.llm.set_default_client(oc)
- Pemilihan Tes
- Giskard menyediakan berbagai jenis pengujian, termasuk pengukuran performa, deteksi bias, dan evaluasi keamanan. Pengguna dapat memilih tes yang paling relevan dengan tujuan mereka. Untuk RAG kali ini, pengukuran performa dilakukan (RAG Evaluation Toolkit).
- Membuat Test Set
- Tahap pertama yang dapat dilakukan Giskard adalah membuat test set secara otomatis. Tetapi jika tidak ingin secara otomatis bisa dimasukkan test set secara manual. Contoh implementasi untuk membuat test set secara otomatis dari Giskard:
from giskard.rag import generate_testset
from giskard.rag.question_generators import simple_questions, complex_questions, situational_questions, double_questions
test_set = generate_testset(
knowledge_base,
num_questions = 50,
language='id',
question_generators=[simple_questions, complex_questions, situational_questions, double_questions],
agent_description = "A chatbot answering questions based on document, please formulate the question and answer in Bahasa Indonesia"
)
- Terdapat beberapa jenis pertanyaan yang dapat dibuat oleh giskard:
- Simple Questions: Pertanyaan sederhana yang dihasilkan dari kutipan basis pengetahuan. Contoh: “Apa ibu kota Prancis?”
- Complex Questions: Pertanyaan yang dibuat lebih kompleks dengan parafrase. Contoh: “Apa nama ibu kota negara Victor Hugo?”
- Distracting Questions: Pertanyaan yang dibuat untuk membingungkan bagian pengambilan RAG dengan elemen yang mengganggu dari basis pengetahuan tetapi tidak relevan dengan pertanyaan. Contoh: “Italia memang indah, tapi apa ibu kota Prancis?”
- Situational Questions: Pertanyaan yang menyertakan konteks pengguna untuk mengevaluasi kemampuan generasi dalam menghasilkan jawaban yang relevan sesuai dengan konteksnya. Contoh: “Saya merencanakan perjalanan ke Eropa, apa ibu kota Prancis?”
- Double Questions: Pertanyaan dengan dua bagian yang berbeda untuk mengevaluasi kemampuan penulis ulang query RAG. Contoh: “Apa ibu kota dan jumlah penduduk Prancis?”
- Conversational: Pertanyaan yang dibuat sebagai bagian dari percakapan, pesan pertama menjelaskan konteks pertanyaan yang ditanyakan di pesan terakhir, juga menguji penulis ulang. Contoh: “Saya ingin mengetahui beberapa informasi tentang Prancis. Apa ibu kotanya?”
- Menjalankan Evaluasi dan Membuat Report
- Evaluasi menggunakan Giskard juga cukup simple, cukup menggunakan fungsi yang telah disediakan pada Python sebagai berikut.
from giskard.rag import evaluate
# Wrap your RAG model
def get_answer_fn(question: str, history=None) -> str:
"""A function representing your RAG agent."""
# Format appropriately the history for your RAG agent
messages = history if history else []
messages.append({"role": "user", "content": question})
# Get the answer
answer = get_answer_from_agent(messages) # could be langchain, llama_index, etc.
return answer
# Run the evaluation and get a report
report = evaluate(get_answer_fn, testset=testset, knowledge_base=knowledge_base)- Analisis Hasil
- Giskard menyajikan hasil pengujian secara terperinci, termasuk metrik performa, potensi masalah, dan rekomendasi perbaikan untuk setiap komponen dalam pipeline.
- Ada beberapa metriks pada Giskard untuk mengukur performa RAG
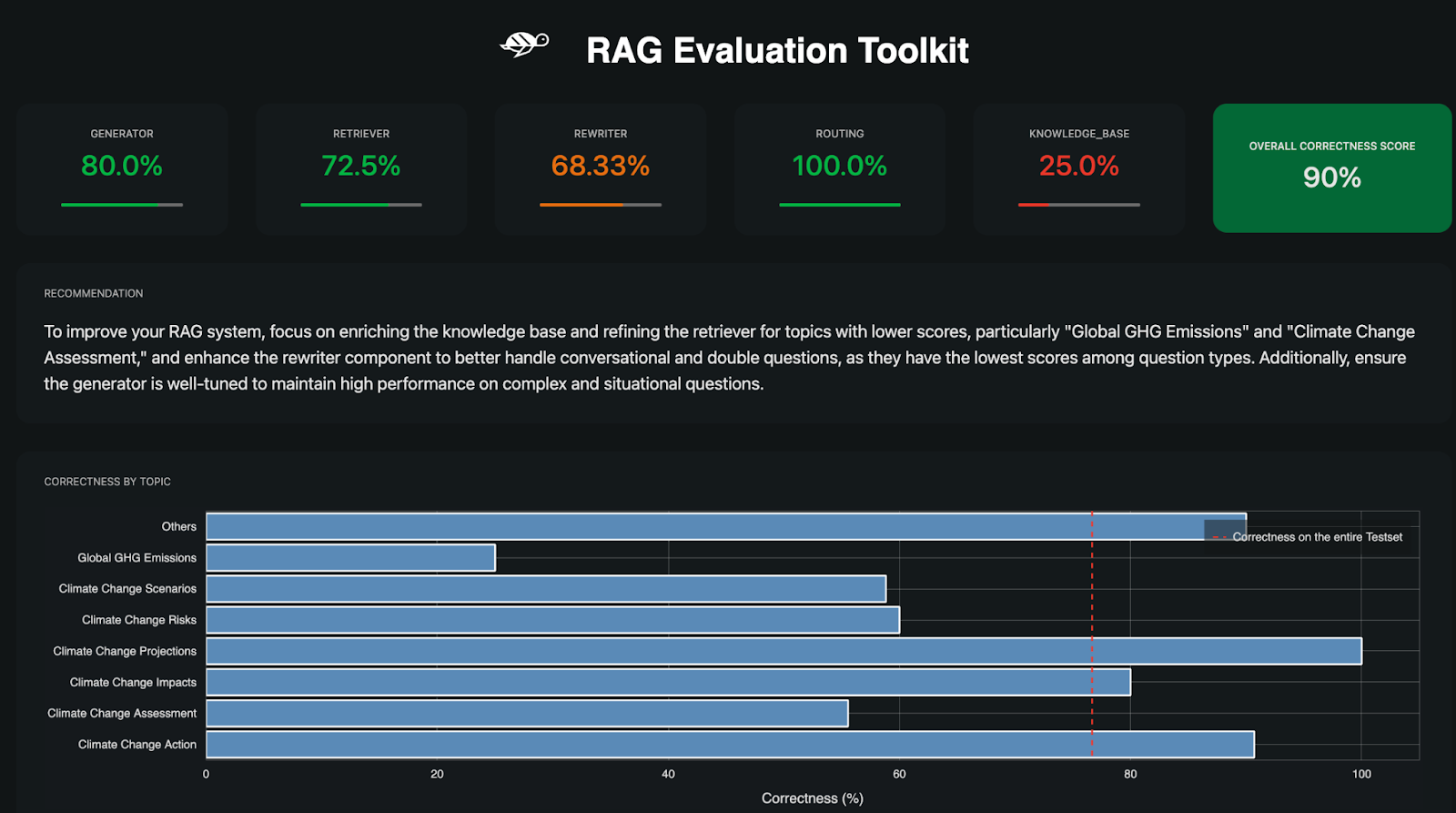
- Generator
- Menghasilkan respons dari Large Language Models (LLM).
- Giskard mengevaluasi kualitas respons berdasarkan relevansi, keselarasan semantik, dan ketepatan konteks.
- Retriever
- Mengambil data relevan dari knowledge base.
- Giskard mengukur presisi dan cakupan retriever untuk memastikan informasi yang diberikan relevan dengan query.
- Rewriter
- Mengubah query pengguna agar lebih relevan dengan knowledge base.
- Giskard memastikan query yang dihasilkan tetap sesuai dengan maksud awal pengguna.
- Routing
- Menyaring query berdasarkan intensinya dan mengarahkan ke jalur yang sesuai.
- Giskard mengevaluasi keakuratan routing dalam memetakan intensi dengan tepat.
- Knowledge Base
- Sumber data eksternal yang digunakan untuk menjawab query.
- Giskard memvalidasi kelengkapan dan relevansi data di dalam knowledge base.
- Berikut merupakan implementasi untuk memasukkan knowledge base ke dalam Giskard:
from giskard.rag import KnowledgeBase
knowledge_base = KnowledgeBase(pd.DataFrame(d.page_content for d in document)) # In this case, is the content in the document we have made into dataframe
knowledge_base
- Perbaikan dan Iterasi
- Berdasarkan hasil yang diberikan, pengembang dapat melakukan perbaikan pada model. Setelah itu, Giskard digunakan kembali untuk memastikan perbaikan telah berhasil diterapkan.
Mengapa Giskard Lebih Unggul?
Giskard memiliki beberapa keunggulan yang mengatasi kelemahan mendasar dari metode evaluasi otomatis seperti RAGAS, BERTScore, dan Levenshtein Distance. Berikut ini alasan mengapa Giskard menjadi pilihan yang lebih andal dalam mengevaluasi sistem Retrieval-Augmented Generation (RAG):
- Kemampuan untuk men-generate test set secara otomatis
Giskard dilengkapi dengan fitur untuk menghasilkan test set secara otomatis, sehingga sangat membantu dalam melakukan benchmark secara scalable. Hal ini menghemat waktu dan tenaga, terutama ketika jumlah data uji yang dibutuhkan sangat besar atau bervariasi. Dengan cara ini, pengujian dapat dilakukan lebih cepat dan efisien tanpa mengorbankan kualitas.
- Hasil yang lebih konsisten dan akurat
Giskard membuktikan keunggulannya dengan memberikan hasil evaluasi yang konsisten dan akurat dibandingkan alat benchmarking lainnya. Konsistensi di sini berarti bahwa nilai evaluasi yang dihasilkan oleh Giskard konsisten dengan hasil evaluasi manual, menunjukkan keandalan alat ini dalam menilai performa model secara objektif.
Sebagai contoh, saya mengevaluasi dua pipeline RAG yang menggunakan LLM berbeda sebagai generator: OpenAI GPT-4 dan Llama 3 8B. Hasil pengujian menunjukkan skor yang berdekatan untuk kedua model, menegaskan konsistensi evaluasi Giskard. Untuk memverifikasi lebih jauh, saya membandingkan hasil evaluasi otomatis dari Giskard dengan evaluasi manual. Skor otomatis Giskard sebesar 78% sejalan dengan evaluasi manual, yang menunjukkan akurasi tinggi dan minim bias dalam pengujian.
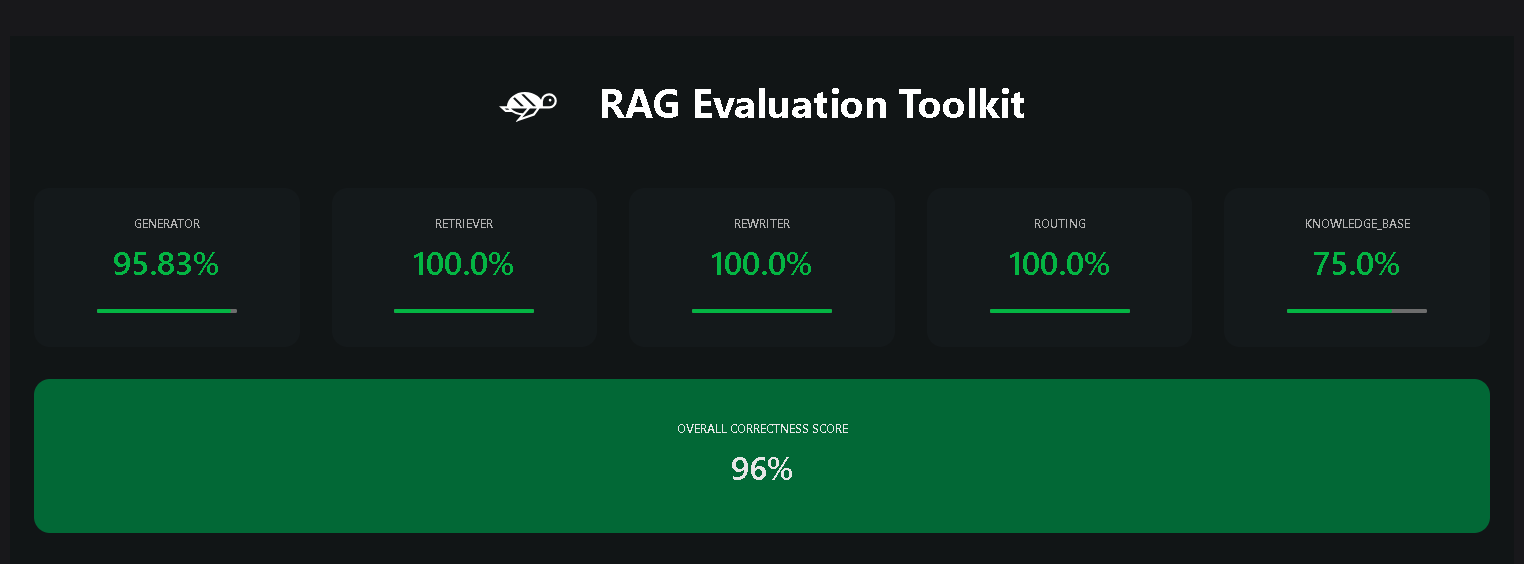

Hasil Pengujian Giskard (Llama 3 8B)
Keandalan hasil evaluasi ini membuat saya semakin yakin bahwa Giskard adalah alat yang tepat untuk meningkatkan pengembangan pipeline RAG saya ke tingkat berikutnya. Alat ini memungkinkan pengujian yang mendalam dan efisien tanpa mengorbankan kualitas, memberikan kepercayaan diri tambahan dalam memastikan performa model yang optimal.
Berbeda dengan RAGAS yang sering gagal menangkap nuansa konteks dalam evaluasi jawaban, Giskard mampu mengevaluasi respons berdasarkan konteks spesifik dari query dan dokumen yang diambil. Sama seperti contoh kasus pada RAGAS, hasil dari Giskard untuk kasus tersebut adalah TRUE (Correctness) yang artinya Giskard menilai jawaban agen benar karena berhasil mencakup dokumen yang diminta dan memberikan informasi tambahan yang relevan untuk memberikan konteks kepada pengguna. Giskard tidak hanya menilai kesesuaian jawaban berdasarkan kemiripan teks tetapi juga mempertimbangkan nilai informasi tambahan yang relevan. Dalam kasus tersebut, informasi seperti langkah-langkah pengajuan, timeline, dan jenis data pendukung dianggap sebagai bagian penting untuk memberikan gambaran lengkap kepada pengguna. Giskard tidak hanya fokus pada kesamaan literal atau frasa tertentu, tetapi juga pada substansi jawaban. Hal ini memungkinkan Giskard untuk menangkap nuansa jawaban, termasuk jika agen memberikan penjelasan lebih luas tetapi tetap sesuai konteks.
- Evaluasi End-to-End yang Komprehensif
Giskard mendukung evaluasi sistem RAG secara holistik, termasuk komponen retrieval dan generatif. Dengan menganalisis performa pada setiap langkah dalam pipeline, Giskard dapat mengidentifikasi titik lemah yang terjadi—apakah masalah berasal dari proses retrieval (pemilihan dokumen yang kurang relevan) atau dari proses generation (jawaban yang kurang tepat). Evaluasi end-to-end ini memberikan gambaran yang lebih lengkap dibandingkan RAGAS yang hanya fokus pada kualitas jawaban akhir.
- Refleksi Kedekatan Semantik Secara Konsisten
Salah satu kelemahan BERTScore dan Levenshtein Distance adalah inkonsistensi dalam mengukur kedekatan semantik antara jawaban model dan jawaban referensi.
- BERTScore sering memberikan skor tinggi untuk jawaban yang tidak sepenuhnya relevan secara semantik.
- Levenshtein Distance, di sisi lain, hanya melihat perbedaan karakter tanpa mempertimbangkan makna teks.
Giskard mengatasi kelemahan ini dengan algoritma canggih yang memastikan kedekatan semantik dievaluasi secara konsisten. Dengan demikian, Giskard mampu memberikan skor yang lebih sesuai dengan makna sebenarnya dari jawaban.
- Dukungan untuk Pengetahuan Domain
Giskard dirancang untuk memahami pengetahuan domain tertentu seperti hukum, medis, atau keuangan. Dengan kemampuan ini, Giskard dapat mengevaluasi respons secara lebih akurat sesuai dengan terminologi dan konteks spesifik dari masing-masing domain. Hal ini menjadikannya lebih unggul dibandingkan metode lain yang sering gagal dalam skenario domain-spesifik.
Dengan kombinasi kemampuan untuk memahami konteks, mengevaluasi pipeline RAG secara menyeluruh, dan merefleksikan kedekatan semantik secara konsisten, Giskard menjadi solusi yang lebih andal dan unggul dalam benchmarking sistem RAG.
Kesimpulan
Berdasarkan pengalaman saya, Giskard adalah tools terbaik untuk benchmarking RAG dibandingkan RAGAS, BERTScore, dan Levenshtein Distance. Keunggulannya terletak pada kemampuannya memberikan hasil evaluasi yang konsisten, akurat, dan sejalan dengan evaluasi manual. Tidak hanya itu, Giskard memungkinkan pengujian menyeluruh hingga ke setiap komponen pipeline RAG, serta memberikan feedback yang jelas untuk perbaikan lebih lanjut. Dengan fitur-fitur canggih seperti otomatisasi pembuatan test set dan evaluasi performa tanpa bias, Giskard menjadi solusi yang andal dan efisien.
Perjalanan saya mencoba berbagai tools benchmarking, seperti RAGAS, BERTScore, dan Levenshtein Distance, memberikan pelajaran berharga mengenai kelemahan dan inkonsistensi masing-masing metode. Pengalaman ini justru memperkuat keyakinan saya bahwa Giskard adalah alat yang paling sesuai untuk memenuhi kebutuhan evaluasi RAG secara mendalam.
Bagi pembaca yang ingin mencoba tools benchmarking, saran saya adalah untuk terlebih dahulu memahami kebutuhan spesifik dari pipeline RAG yang ingin dievaluasi. Jika Anda mencari alat yang mampu memberikan hasil yang presisi, dapat diandalkan, dan mendukung pengembangan model secara menyeluruh, maka Giskard adalah pilihan yang sangat layak dipertimbangkan. Jangan ragu untuk mengeksplorasi fitur-fiturnya dan mengintegrasikannya ke dalam alur kerja Anda. Pengalaman saya menunjukkan bahwa Giskard bukan hanya alat evaluasi, tetapi juga partner dalam memastikan keberhasilan model RAG Anda.

0 Comments
Leave A Comment